 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolLingo: Molecule-Native Representations for LLM-Powered Scientific Agents
May 27, 2026We present MolLingo, a multi-agent system that emulates the reasoning process of a chemist to automate molecular design. Existing LLM-based approaches either operate as standalone generative models without access to external tools or lack the multi-agent coordination and shared memory needed for iterative, evidence-driven reasoning across the molecular design pipeline. MolLingo addresses this by coordinating a Literature Agent, a Chemist Agent, and an Orchestrator through a shared memory module, with each agent equipped with domain-specific tools. To enable effective molecular reasoning, we introduce BRICS-based Fragment Enumeration (BFE), a synthesis-aware molecular fragmentation method that decomposes molecules into chemically meaningful building blocks represented as block-based SMILES paired with common chemical names. This representation bridges molecular structure and LLM semantic space, enabling block-level reasoning and editing that is difficult with raw SMILES alone. As a case study in early-stage therapeutic design, MolLingo further grounds the Chemist Agent's reasoning in binding site geometry and residue-level protein context derived from molecular docking to optimize molecules for stronger target binding. Across four benchmarks, MolLingo consistently outperforms frontier LLMs and specialized baselines, including a fourfold docking score improvement over GPT-5.4 despite using the same underlying model, consistent drug property optimization gains across multiple LLM backbones, and state-of-the-art results on TOMG-Bench, surpassing both frontier LLMs and the RL-based optimization method RePO. Our results suggest that LLMs are already capable molecular design assistants when guided through chemically meaningful representations and biologically grounded structural context. Code is available at: https://anonymous.4open.science/status/MolLingo-7450.
Personal Visual Memory from Explicit and Implicit Evidence
May 27, 2026Long-term memory is increasingly important for personalized AI agents, yet existing benchmarks and methods remain largely text-centric. Even when images are included, the user-specific information needed for later questions is typically recoverable from text alone, and most memory systems reduce image turns to generic captions. Yet images often carry personal information that text rarely states -- both explicit evidence, such as recurring user-associated entities, and implicit evidence, such as latent user facts inferred from visual or multimodal cues. We introduce a benchmark for personal visual memory that targets both forms of evidence, and propose VisualMem, a hybrid visual--text architecture that augments a text-memory backend with a structured personal visual memory module. Rather than collapsing images into captions, VisualMem uses conversational context to resolve identity, ownership, and durable user facts. Experiments show that VisualMem substantially outperforms prior memory systems on our benchmark while remaining competitive on standard text-memory benchmarks, indicating that personal visual memory is a distinct and important component of long-term memory for personalized AI agents.
Meanings and Measurements: Multi-Agent Probabilistic Grounding for Vision-Language Navigation
Mar 19, 2026Robots collaborating with humans must convert natural language goals into actionable, physically grounded decisions. For example, executing a command such as "go two meters to the right of the fridge" requires grounding semantic references, spatial relations, and metric constraints within a 3D scene. While recent vision language models (VLMs) demonstrate strong semantic grounding capabilities, they are not explicitly designed to reason about metric constraints in physically defined spaces. In this work, we empirically demonstrate that state-of-the-art VLM-based grounding approaches struggle with complex metric-semantic language queries. To address this limitation, we propose MAPG (Multi-Agent Probabilistic Grounding), an agentic framework that decomposes language queries into structured subcomponents and queries a VLM to ground each component. MAPG then probabilistically composes these grounded outputs to produce metrically consistent, actionable decisions in 3D space. We evaluate MAPG on the HM-EQA benchmark and show consistent performance improvements over strong baselines. Furthermore, we introduce a new benchmark, MAPG-Bench, specifically designed to evaluate metric-semantic goal grounding, addressing a gap in existing language grounding evaluations. We also present a real-world robot demonstration showing that MAPG transfers beyond simulation when a structured scene representation is available.
Group Diffusion: Enhancing Image Generation by Unlocking Cross-Sample Collaboration
Dec 11, 2025



In this work, we explore an untapped signal in diffusion model inference. While all previous methods generate images independently at inference, we instead ask if samples can be generated collaboratively. We propose Group Diffusion, unlocking the attention mechanism to be shared across images, rather than limited to just the patches within an image. This enables images to be jointly denoised at inference time, learning both intra and inter-image correspondence. We observe a clear scaling effect - larger group sizes yield stronger cross-sample attention and better generation quality. Furthermore, we introduce a qualitative measure to capture this behavior and show that its strength closely correlates with FID. Built on standard diffusion transformers, our GroupDiff achieves up to 32.2% FID improvement on ImageNet-256x256. Our work reveals cross-sample inference as an effective, previously unexplored mechanism for generative modeling.
Relational Visual Similarity
Dec 08, 2025



Humans do not just see attribute similarity -- we also see relational similarity. An apple is like a peach because both are reddish fruit, but the Earth is also like a peach: its crust, mantle, and core correspond to the peach's skin, flesh, and pit. This ability to perceive and recognize relational similarity, is arguable by cognitive scientist to be what distinguishes humans from other species. Yet, all widely used visual similarity metrics today (e.g., LPIPS, CLIP, DINO) focus solely on perceptual attribute similarity and fail to capture the rich, often surprising relational similarities that humans perceive. How can we go beyond the visible content of an image to capture its relational properties? How can we bring images with the same relational logic closer together in representation space? To answer these questions, we first formulate relational image similarity as a measurable problem: two images are relationally similar when their internal relations or functions among visual elements correspond, even if their visual attributes differ. We then curate 114k image-caption dataset in which the captions are anonymized -- describing the underlying relational logic of the scene rather than its surface content. Using this dataset, we finetune a Vision-Language model to measure the relational similarity between images. This model serves as the first step toward connecting images by their underlying relational structure rather than their visible appearance. Our study shows that while relational similarity has a lot of real-world applications, existing image similarity models fail to capture it -- revealing a critical gap in visual computing.
RainDiff: End-to-end Precipitation Nowcasting Via Token-wise Attention Diffusion
Oct 16, 2025Precipitation nowcasting, predicting future radar echo sequences from current observations, is a critical yet challenging task due to the inherently chaotic and tightly coupled spatio-temporal dynamics of the atmosphere. While recent advances in diffusion-based models attempt to capture both large-scale motion and fine-grained stochastic variability, they often suffer from scalability issues: latent-space approaches require a separately trained autoencoder, adding complexity and limiting generalization, while pixel-space approaches are computationally intensive and often omit attention mechanisms, reducing their ability to model long-range spatio-temporal dependencies. To address these limitations, we propose a Token-wise Attention integrated into not only the U-Net diffusion model but also the spatio-temporal encoder that dynamically captures multi-scale spatial interactions and temporal evolution. Unlike prior approaches, our method natively integrates attention into the architecture without incurring the high resource cost typical of pixel-space diffusion, thereby eliminating the need for separate latent modules. Our extensive experiments and visual evaluations across diverse datasets demonstrate that the proposed method significantly outperforms state-of-the-art approaches, yielding superior local fidelity, generalization, and robustness in complex precipitation forecasting scenarios.
NaturalThoughts: Selecting and Distilling Reasoning Traces for General Reasoning Tasks
Jul 02, 2025



Recent work has shown that distilling reasoning traces from a larger teacher model via supervised finetuning outperforms reinforcement learning with the smaller student model alone (Guo et al. 2025). However, there has not been a systematic study of what kind of reasoning demonstrations from the teacher are most effective in improving the student model's reasoning capabilities. In this work we curate high-quality "NaturalThoughts" by selecting reasoning traces from a strong teacher model based on a large pool of questions from NaturalReasoning (Yuan et al. 2025). We first conduct a systematic analysis of factors that affect distilling reasoning capabilities, in terms of sample efficiency and scalability for general reasoning tasks. We observe that simply scaling up data size with random sampling is a strong baseline with steady performance gains. Further, we find that selecting difficult examples that require more diverse reasoning strategies is more sample-efficient to transfer the teacher model's reasoning skills. Evaluated on both Llama and Qwen models, training with NaturalThoughts outperforms existing reasoning datasets such as OpenThoughts, LIMO, etc. on general STEM reasoning benchmarks including GPQA-Diamond, MMLU-Pro and SuperGPQA.
ProteinZero: Self-Improving Protein Generation via Online Reinforcement Learning
Jun 09, 2025
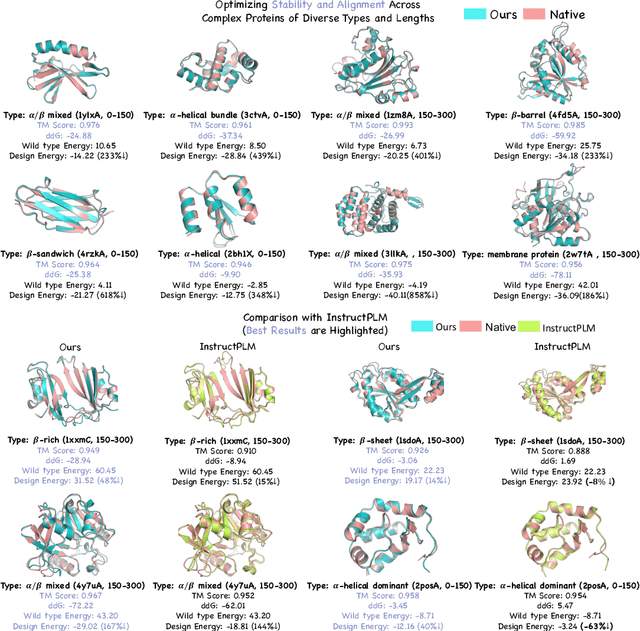
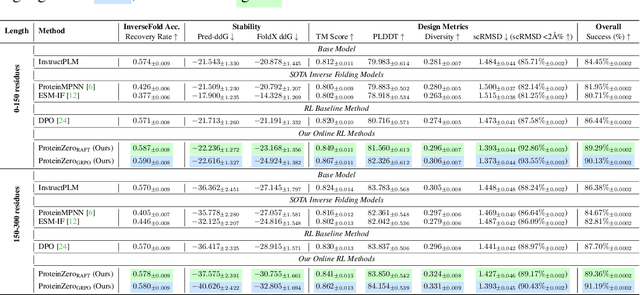

Protein generative models have shown remarkable promise in protein design but still face limitations in success rate, due to the scarcity of high-quality protein datasets for supervised pretraining. We present ProteinZero, a novel framework that enables scalable, automated, and continuous self-improvement of the inverse folding model through online reinforcement learning. To achieve computationally tractable online feedback, we introduce efficient proxy reward models based on ESM-fold and a novel rapid ddG predictor that significantly accelerates evaluation speed. ProteinZero employs a general RL framework balancing multi-reward maximization, KL-divergence from a reference model, and a novel protein-embedding level diversity regularization that prevents mode collapse while promoting higher sequence diversity. Through extensive experiments, we demonstrate that ProteinZero substantially outperforms existing methods across every key metric in protein design, achieving significant improvements in structural accuracy, designability, thermodynamic stability, and sequence diversity. Most impressively, ProteinZero reduces design failure rates by approximately 36% - 48% compared to widely-used methods like ProteinMPNN, ESM-IF and InstructPLM, consistently achieving success rates exceeding 90% across diverse and complex protein folds. Notably, the entire RL run on CATH-4.3 can be done with a single 8 X GPU node in under 3 days, including reward computation. Our work establishes a new paradigm for protein design where models evolve continuously from their own generated outputs, opening new possibilities for exploring the vast protein design space.
Variational Supervised Contrastive Learning
Jun 09, 2025Contrastive learning has proven to be highly efficient and adaptable in shaping representation spaces across diverse modalities by pulling similar samples together and pushing dissimilar ones apart. However, two key limitations persist: (1) Without explicit regulation of the embedding distribution, semantically related instances can inadvertently be pushed apart unless complementary signals guide pair selection, and (2) excessive reliance on large in-batch negatives and tailored augmentations hinders generalization. To address these limitations, we propose Variational Supervised Contrastive Learning (VarCon), which reformulates supervised contrastive learning as variational inference over latent class variables and maximizes a posterior-weighted evidence lower bound (ELBO) that replaces exhaustive pair-wise comparisons for efficient class-aware matching and grants fine-grained control over intra-class dispersion in the embedding space. Trained exclusively on image data, our experiments on CIFAR-10, CIFAR-100, ImageNet-100, and ImageNet-1K show that VarCon (1) achieves state-of-the-art performance for contrastive learning frameworks, reaching 79.36% Top-1 accuracy on ImageNet-1K and 78.29% on CIFAR-100 with a ResNet-50 encoder while converging in just 200 epochs; (2) yields substantially clearer decision boundaries and semantic organization in the embedding space, as evidenced by KNN classification, hierarchical clustering results, and transfer-learning assessments; and (3) demonstrates superior performance in few-shot learning than supervised baseline and superior robustness across various augmentation strategies.
Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models
Jun 05, 2025Scaling laws predict that the performance of large language models improves with increasing model size and data size. In practice, pre-training has been relying on massive web crawls, using almost all data sources publicly available on the internet so far. However, this pool of natural data does not grow at the same rate as the compute supply. Furthermore, the availability of high-quality texts is even more limited: data filtering pipelines often remove up to 99% of the initial web scrapes to achieve state-of-the-art. To address the "data wall" of pre-training scaling, our work explores ways to transform and recycle data discarded in existing filtering processes. We propose REWIRE, REcycling the Web with guIded REwrite, a method to enrich low-quality documents so that they could become useful for training. This in turn allows us to increase the representation of synthetic data in the final pre-training set. Experiments at 1B, 3B and 7B scales of the DCLM benchmark show that mixing high-quality raw texts and our rewritten texts lead to 1.0, 1.3 and 2.5 percentage points improvement respectively across 22 diverse tasks, compared to training on only filtered web data. Training on the raw-synthetic data mix is also more effective than having access to 2x web data. Through further analysis, we demonstrate that about 82% of the mixed in texts come from transforming lower-quality documents that would otherwise be discarded. REWIRE also outperforms related approaches of generating synthetic data, including Wikipedia-style paraphrasing, question-answer synthesizing and knowledge extraction. These results suggest that recycling web texts holds the potential for being a simple and effective approach for scaling pre-training data.